Defect Process is a 2D hack n’ slash platform game released on Steam and implemented in Haskell. The interesting thing is that the partial source code was released on GitHub, available to be cloned, built and executed (if you own a copy of Defect Process).
Although the developers have written a short Defect Process Overview which is great for a start, in the following I attempt a more in-depth analysis of the highly interesting architecture of Defect Process. The hope is to take away learnings in terms of Haskell as well as Game Engine architecture, both topics very dear to my heart.
- The Defect Process source code discussed is the commit f5f4abcd9ad0e09b1fc2f8b2d44600194934e9ef.
- I am not discussing the actual game logic (for example how player mechanis or enemy behaviours are implemented) but am primarily interested in the architecture, that is how the game loop works and how the subsystems are conneted.
- I am briefly discussing and relating to certain concepts from Game Engines for which I recommend the great book Game Engine Architeture.
Cloc ¶
In a first step I have used cloc to see with what amount of source code I am dealing with.
Version 1.86 (Ubuntu 21.10)
426 text files.
426 unique files.
25 files ignored.
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Haskell 397 5079 116 32690
C 2 269 5 1098
YAML 2 8 2 102
Markdown 5 23 0 98
-------------------------------------------------------------------------------
SUM: 406 5379 123 33988
-------------------------------------------------------------------------------
32+k lines of Haskell code is quite something. Given the fact how compact and concise we can write code in Haskell, we can assume that this amount of code would probably amount to at least 100k LoC in an OO language such as Java.
The next step was to build the game. The GitRepo contains excellent instructions on how to build the game on Linux, Mac and Windows. I am using Linux and needed to set the PKG_CONFIG_PATH (see https://stackoverflow.com/questions/25713200/cant-install-sdl2-via-cabal/28218449#28218449). Also, when building with Game Audio, LD_LIBRARY_PATH needs to be set to /lib to work. Apart from that building and running it is super easy (given you have bought a copy on Steam).
Three Layer Haskell Cake ¶
The Defect Process Overview mentions that the top level design is very similar to Three Layer Haskell Cake, pointing to src/AppEnv/Types.hs as starting point. Let’s have a closer look at this approach, to properly understand the backbone of the Game.
In the Three Layer Haskell Cake the application is basically built around a ReaderT SomeAppData m type with m being a Monad, often IO to have access to the outside world when needed. Defect Process has this as well, running in IO but on the data-side splitting SomeAppData into a read- and write part.
newtype AppEnv p a = AppEnv (ReaderT AppEnvReadData (StateT AppEnvWriteData IO) a)
deriving newtype
( Functor
, Applicative
, Monad
, MonadReader AppEnvReadData
, MonadState AppEnvWriteData
, MonadIO
, MonadCatch
, MonadThrow
, MonadRandom
)
There are the obvious deriving instances including MonadReader for the read-only AppEnvReadData and MonadState for the AppEnvWriteData. Looking closer at AppEnv reveals that p is a phantom type, which is an interesting twist on the Three Layer Haskell Cake approach. The phantom type is used to execute specific message phases, but more on that later.
To fully understand AppEnv we need to look at both AppEnvReadData and AppEnvWriteData.
AppEnvWriteData ¶
The AppEnvWriteData looks simple, it is just a Map of MsgId to lists of MsgInternal.
data AppEnvWriteData = AppEnvWriteData
{ _messages :: M.Map MsgId [MsgInternal]
}
Although it is “just” such a small type, it is worth investigating MsgId and MsgInternal closer as Defect Process is effectively built around a message-passing flow, which drives the engine (see Message Passing Rules Everything Around Me in the Defect Process Overview).
MsgId is basically a type-safe wrapper around Data.Unique for MsgInternal values. MsgInternal represents a message, which has a receiver identified by _to, a processing _order (Front, Normal, After Normal, End) and a _payload.
data MsgInternal = MsgInternal
{ _payload :: MsgPayload
, _to :: MsgId
, _order :: MsgOrder
}
The interesting part is the payload, which can be understood to be the type of message, holding all relevant data to communicate to the receiver. It is defined in src/Msg/Payload.hs (actually also in src/Msg/Payload.hs-boot which is required to compile mutually recursive modules)
data MsgPayload
= AudioMsgPayload' AudioMsgPayload
| CollisionMsgPayload' CollisionMsgPayload
| ConsoleMsgPayload' ConsoleMsgPayload
| EnemyMsgPayload' EnemyMsgPayload
| HurtMsgPayload' HurtMsgPayload
| InfoMsgPayload' InfoMsgPayload
| MenuMsgPayload' MenuMsgPayload
| RoomMsgPayload' RoomMsgPayload
| ParticleMsgPayload' ParticleMsgPayload
| PlayerMsgPayload' PlayerMsgPayload
| ProjectileMsgPayload' ProjectileMsgPayload
| NewThinkProjectileMsgPayload' NewThinkProjectileMsgPayload
| NewUpdateProjectileMsgPayload' NewUpdateProjectileMsgPayload
| UiMsgPayload' UiMsgPayload
| WorldMsgPayload' WorldMsgPayload
There we see message payload types for all subsystems in the game: Audio, Collision Detection, Enemies, Damage, Menus, Rooms, Particles, Player, Projectiles, Ui, World,… The great thing is that the Payload definitions are pretty much self-explanatory, therefore lets look at parts of some of them.
AudioMsgPayload.AudioMsgPlaySound is used to trigger the playback of a sound specified in the FilePath and placed at a specific 2D position in the world (which is passed to the FMOD audio engine which then plays it relative to the player).
data AudioMsgPayload
= AudioMsgPlaySound FilePath Pos2
...
ConsoleMsgPayload has many data constructors which all trigger events when working on the console (which is necessary when using the free GitHub build). For example to print some text to the Console the ConsoleMsgPrint data constructor which holds some Text is used.
data ConsoleMsgPayload
= ConsoleMsgPrint T.Text
...
The largest and most complex MsgPayload is the one related to player messages, that is PlayerMsgPayload. We see that for more flexibilitiy it is implemented as a GADT. For example there exists the PlayerMsgSetVelocity constructor to change the velocity of the player to a given value specified in a Vel2 (a 2-component Float product type).
data PlayerMsgPayload where
PlayerMsgSetVelocity :: Vel2 -> PlayerMsgPayload
...
To change rooms the WorldMsgPayload is used with the WorldMsgSwitchRoom constructor.
data WorldMsgPayload
= WorldMsgSwitchRoom RoomType PosY
...
There are many more messages but now we have a pretty good idea of the Messages which can be written into the Map of AppEnvWriteData.
With messages the fundamentally important question where and when they are processed is unanswered so far. The answer lies in the understanding of the Game Loop, but first lets have a closer look at AppEnvReadData.
AppEnvReadData ¶
AppEnvReadData holds the read-only data available in AppEnv through the ReaderT and MonadReader respectively.
data AppEnvReadData = AppEnvReadData
{ _graphics :: Graphics
, _inputState :: InputState
, _configs :: Configs
, _fileCacheData :: FileCacheData
, _asyncRequestQueue :: TQueue AsyncRequest
, _asyncDataQueue :: TQueue AsyncData
, _asyncSignalQueue :: TQueue AsyncSignal
}
Graphicsis a record type, holding the SDL Window, Fonts, Cursors, and more importantly amongst others the Cameras position, offset and space. All the camera attributes are contained inIORefs, therefore they can be mutated (even if we get the IORefs from the ReaderT!).InputStateis also a record type, holding the input information for the current frame, is updated every frame (we will see how further down below), therefore not having any IORefs. It contains the current mouse position, pressed mouse buttons, keyboard buttons pressed, and other input related information.Configsis a record type as well, which holds all the games configurations, which can be found underdata/configs(if you own the game). The configs define the rough outline of each level, as well as defining enemies, player parameters and weapons.FileCacheDatais (probably) responsible for caching loaded files such as tetures, audio and others.
AppEnvReadData also holds three TQueues: AsyncRequest, AsyncData and AsyncSignal.
- AsyncRequest is used to communicate a request for some asynchronous operation.
- AsyncData is used to enqueue the result of an asynchronous operation.
- AsyncSignal is to actually trigger the processing of the data produced by the asynchronous operations.
This is quite a generic explanation so far, but looking at AsyncRequest, AsyncData and AsyncSignal reveals a little more about its intentions:
data AsyncRequest
= PreloadPackFileRequest FilePath
| PreloadRoomFgBgPackFilesRequest RoomType
data AsyncData
= SdlSurfaceData FilePath SDL.Surface
data AsyncSignal
= DoMainThreadLoadsSignal
It is much clearer now: these queues are used to asynchronously load files and rooms in the background so not to block the game loop. This is a concept found in many modern game engines, to avoid stuttering and hickups in the main loop due to the comparatively high latency when bringing in resources from the storage (even if it is an SDD). For example Naughty Dogs current game engine uses the OS thread to bring in resources from storage or do networking because the OS thread is high latency because being IO bound due to the OS having priority (see Parallelizing the Naughty Dog Engine and accompanying slides)
Lets have a look where the AsyncRequest are generated. We have three points in the game engine where this happens:
Level.Room.preloadRoomDeferredPackResourcesrequests PreloadPackFileRequestLevel.Room.ArenaWalls.preloadRoomArenaWallsPackResourcesrequests PreloadPackFileRequestAsync.MainThreadchangeWorldRoomInternalrequests PreloadRoomFgBgPackFilesRequest
Where are they processed though? It is in Async.BackgroundThread.forkBackgroundThread, there a thread is forked which checks forever AsyncRequest arrivals on _asyncRequestQueue and processes them to put them as AsyncData into _asyncDataQueue.
So far so good, but where is AsyncData _asyncDataQueue processed? In Async.MainThread.loadMainThreadAsyncData. Without going into too much detail, this function is checking if AsyncSignal _asyncSignalQueue is present and then waits (repeatedly checking with a small timeout) until AsyncRequest _asyncRequestQueue is empty. As soon as it is empty all SdlSurfaceData values from _asyncDataQueue are read and loaded as tetures through a call to loadTextureEx in Window.Graphics.Texture.
But where does AsyncSignal come from which triggers the processing of the data? The DoMainThreadLoadsSignal is triggered in World.changeWorldRoomInternal.
Long, complex story short: the main thread waits until no more AsyncRequests are pending, that is AsyncRequest queue is empty. That is the case if the background thread has finished processing the preloading of all files during which the background thread will put the resulting data into the _asyncDataQueue. As soon as this is finished, the main thread is signaled with DoMainThreadLoadsSignal by World.changeWorldRoomInternal to start processing the _asyncDataQueue to load the textures using loadTextureEx.
Now this ping-ponging between background thread and main thread seems to be unncessarily complex and you might wonder why this is necessary. The sole reason for it is that because all rendering and SDL-related activities have to be performed from the main thread due to SDL internals and loading of textures is no exception to this rule. Thus, loading of files (textures, sound) from the storage is offloaded to the background thread to avoid blocking the main thread but then transferring the loaded data to the main thread so that it can load textures into SDL.
Capabilities ¶
AppEnv.Types.hs implements a number of instances on AppEnv, which are instances of various type classes defined in other modules. These type classes and their AppEnv instances are what Matt Parsons called capabilities in his Three Layer Haskell Cake article - they simply define what AppEnv is capable of. Amongst others the capabilities are:
Reading and Writing Messages (type classes defined in Msg.Types.hs):
instance MsgsRead p (AppEnv p) where
readMsgsTo :: AllowMsgRead p a => MsgId -> AppEnv p [a]
...
instance MsgsWrite p (AppEnv p) where
writeMsgs :: [Msg p] -> AppEnv p ()
...
Reading from the configuration (type class defined in Configs.hs):
instance ConfigsRead (AppEnv p) where
readConfig :: (Configs -> a) -> (a -> b) -> AppEnv p b
...
As well as reading and writing the Graphics, Input and AsyncRequest, AsyncData and AsyncSignal.
This should give us a good overview over AppEnv and its capablities which form the structural backbone of the engine. We are now ready to dive into the actual execution flow of the engine, that is, we are going to examine Defect Process’ Game Loop.
Game Loop ¶
Every computer game can be basically classified as a soft real-time interactive agent-based computer simulation. Let’s break this down:
- Soft Real-Time: games try to deliver at least 30 frames per second and up to 60 for a smoother experience. This is only a soft target however, which can vary from hardware to hardware and more importantly, from scene to scene, depending on the complexity. Hard real-time would be required if there are serious consequences if a given performance goal is not reached, which is the case in certain robotics and control devices. For games the worst what can happen is that the player is going to have a dia show instead of an interactive, smooth experience. Note: the 120Hz the Defect Process Overview mentions are not the frame rate but the (physics) simulation rate, see below.
- Interactive: this simply means, that the game takes input from the player, subsequently altering the gaming experience (generating a feedback, and so on).
- Computer Simulation: computer simulations essentially simulate dynamics of various kinds over some virtual time, for example fluid dynamics, spreading of infectious diseases, crowd behaviour,… Computer games are in their core computer simulations as they simulate the behavior of (dynamic) game objects over time, which in the case of games is the wall-clock real-time. This simulation is effectively a large number of numerical pure computations. The 120Hz which are mentioned in the Defect Process Overview concern the number of updates the (physics) simulation is run per second. Generally, physics simulations do various types of numerical integration (with the Euler Integration being most common) and are numerically most stable when updated with a fixed and sufficiently high rate per second. The Defect Process Overview links to an article where this is described more in-depth (more on that below).
- Agent-Based: this is a specific type of one of the three major computer simulations methodologies (the others being System Dynamics and Discrete Event Simulation). In Agent-Based Simulation a system is modeled through its constituting parts and their interactions, which when simulated give rise to the emergent behaviour of the system as a whole. For computer games the game objects are the “agents”, the constituting parts of the “system”. Equally, we see emergent behaviour in games as the actual gaming experience the player goes through.
The fact that computer games are soft real-time interactive agent-based computer simulation means that every game has at its heart a Game Loop, which generally executes as often as possible per second, but at least 30 times. From the Game Loop various subsystems are serviced such as Input, Audio, Rendering, AI, Physics and others. Of course, Defect Process is not different, with the main Game Loop implemented as a tail recursive call, which simplified looks like:
gameMain :: World -> IO World
gameMain world = do
world' <- updateWorld world
gameMain world'
So ultimately the game loop just updates the world as often as possible, which obviously includes reading input, simulating the world state, rendering, servicing audio, and other stuff. This top-level understanding is helpful for a first understanding but we want to dig deeper to actually understand how exactly the Game Loop works. More specifically we want to know how the subsystems are serviced, when and how the actual world (physics) simulation is computed, how the player is updated and how rendering is done. For this we want to break the Game Loop code down as much as necessary. From this we also hope to properly understand the actual execution flow in the game and therefore its Game Engine Architecture, that is the glue which interconnects all parts of the game.
It all beginns in main :: IO () of Main.hs which loads configurations, initialises SDL and the fullscreen window as well as AppEnvData. Note that AppEnvData is not the AppEnv of the Three Layer Haskell Cake! It is a record type which holds AppEnvReadData and AppEnvWriteData, which will be used to run AppEnv actions. This makes sense: AppEnv defines the interface or capabilities through a monadic interface, and AppEnvData is the actual underlying data needed to execute the capabilities. The execution is implemented in AppEnv.runAppEnv:
runAppEnv :: AppEnvData -> AppEnv BaseMsgsPhase a -> IO a
runAppEnv appEnvData (AppEnv appEnv) = evalStateT (runReaderT appEnv envReadData) envWriteData
where
envReadData = _readData appEnvData
envWriteData = _writeData appEnvData
Nothing surprising here: the monad transformer stack is executed layer by layer, feeding the relevant data (_readData, _writeData) to the runners to eventually return an IO action.
After all has been initialised, Main then calls into Game.runGame which is where the game begins properly. First, the BackgroundThread is forked, which means that we have 2 threads in the game engine: the main thread and the newly forked Background Thread. It is worth mentioning that since around 2013, Game Engines have switched to multi-core architectures to make the most use of the computational resources which became available in the console generation at that time (PS4, XBox One both 8 Cores, which seems to be the standard now as PS5 and XBox X Series are still on 8 cores; probably also because modern games are mainly GPU bound and do not scale up beyond 8 cores). Modern game engines then distribute the computations required for each frame in the form of tasks across all cores, thus achieving a nearly 100% utilisation of all cores.
Although Defect Process is forking a background thread, the intention is not to implement a proper multi-core architecture, but to be able to load textures asynchronously into memory without blocking the main thread, guaranteeing a smoother gaming experience. Therefore, altough it is also using multiple threads, the motivation is different, and although the Defect Process Overview mentions Message Passing Rules Everything Around Me as core to the architecture it is not implemented as a concurrent approach but all work is done on the main thread.
You might wonder how then Defect Process achieves what it claims in the Overview: “The simulation runs at a fixed 120hz but renders at any refresh rate”. This does not mean that we have separate threads for rendering and simulation (physics), because we can perform the simulation on the main thread, where also rendering happens, given the main thread happens fast enough. We discuss the details of this further down below.
After the background thread has been forked, the actual game is initialised with mkGame:
game <- runAppEnv appEnvData mkGame
...
mkGame :: AppEnv BaseMsgsPhase Game
...
data Game = Game
{ _mode :: GameMode
, _prevMode :: GameMode
, _world :: World
, _menu :: Menu
, _time :: Time
, _console :: Console
, _quit :: Bool
}
In mkGame FMOD is initialised, various settings read and a new Game value is constructed:
withAppEnvReadData inputState cfgs' $
withMsgsPhase @SetupMsgsPhase $
Game <$>
pure gameMode <*>
pure gameMode <*>
mkWorld <*>
mkMenu <*>
mkTime <*>
mkConsole <*>
pure False
We see the use of withAppEnvReadData :: InputState -> Configs -> AppEnv p a -> AppEnv p a which allows to change the InputState as well as Configs while executing the AppEnv action. This is necessary because InputState and Configs are part of the read-only AppEnvReadData accessible through ReaderT. However, InputState needs to be constructed for every frame and injected in AppEnv because it contains the inputs (mouse position, mouse buttons pressed, keyboard buttons pressed,…) for the current frame - withAppEnvReadData allows to do that (as well as for Configs).
But what is withMsgsPhase doing and why is it necessary? When looking at its implementation there is not much going on:
withMsgsPhase :: AppEnv p a -> AppEnv BaseMsgsPhase a
withMsgsPhase (AppEnv appEnv) = AppEnv appEnv
Basically it just unpacks appEnv and return it unchanged. The crucial difference however is the phantom type p which we mentioned above in the discussion on AppEnv. In the input it is polymorph but in the return type it is fixed to BaseMsgsPhase. When looking at the Game construction it becomes now clear what the purpose of the phantom type p is and why we need withMsgsPhase. Relevant calls to better understand what is going on are:
mkWorld :: AppEnv SetupMsgsPhase World
mkConsole :: AppEnv SetupMsgsPhase Console
Both require an AppEnv with the phantom type p fixed to SetupMsgsPhase. However during the execution of mkGame AppEnv phantom type p is BaseMsgsPhase, therefore this would not type check. To be able to execute calls as mkWorld and mkConsole from within an AppEnv BaseMsgsPhase we need to use withMsgsPhase @SetupMsgsPhase so to “cast” AppEnv to the right “Phase”. This is also probably what the phantom type p stands for: the phase the game is currently in. Using a phantom type to encode the current phase into AppEnv ensures that we cannot accidently perform operations which are not suitable for a given phase - or that we are explicit in casting to another phase, as it is happening in mkGame in the construction of Game.
Let’s continue with runGame. After game has been constructed with mkGame, the ConsoleMsgsPhase actions are executed using withMsgsPhase. Finally, AppEnvData is updated with the previously constructed input and config using updateAppEnvReadData. Then the call is made to the proper tail-recursive game loop: gameMain passing the current AppEnvData, the SDL Window and the initial game state along.
gameMain proper ¶
Lets look closely at gameMain. Here I provide only the type and have replaced the relevant technical details with commentary, leaving just the tail-recursive call.
gameMain :: AppEnvData -> Window -> Game -> IO ()
gameMain appEnvData window game = do
-- 1. update (simulate) game step
-- 2. render graphics
-- => results in updated window' and game'
-- 3. update AppEnvData with current input
-- => results in updated appEnvData'
gameMain appEnvData' window' game'
gameMain receives the AppEnvData to be able to runAppEnv actions, the Window for rendering, the current Game state and runs in IO for obvious reasons. As was already pointed out in the Defect Process Overview it is a tail-recursive function so it can potentially run forever and we see that in the tail-recursive call all three arguments are passed in updated versions.
Updating AppEnvData is not much to say about, rendering graphics I am discussing in a section below, so lets focus on the most interesting part here: simulating one game step, which is implemented in updateGame. In this function, based on the time elapsed since the previous frame, the whole game state is updated. The technical details of this process are highly interesting and treated in sections further down below.
The actual updating of the game state happens in stepGame. It simply services FMOD (the sound engine) and depending whether the game is in the main menu, pause menu, or world, stepGame calls into the specific update function of the respective subsystem. For this article I am only interested in how the world is advanced, that is the call into worldMain and ultimately updateWorld which are both implemented in World.Main.hs.
In updateWorld all dynamic objects (agents) get their turn to act on the current state through think functions and then execute their actions in the world through update functions. Examples for these dynamic objects are obviously the player and enemies but also the level, projectiles and collisions.
This should be enough to basically understand the Game Loop with its execution flow and when and how simulations are done and entities are acting. Below we added a visualisation of the important components of Defect Process’ Game Loop using a simple Sequence Diagram.
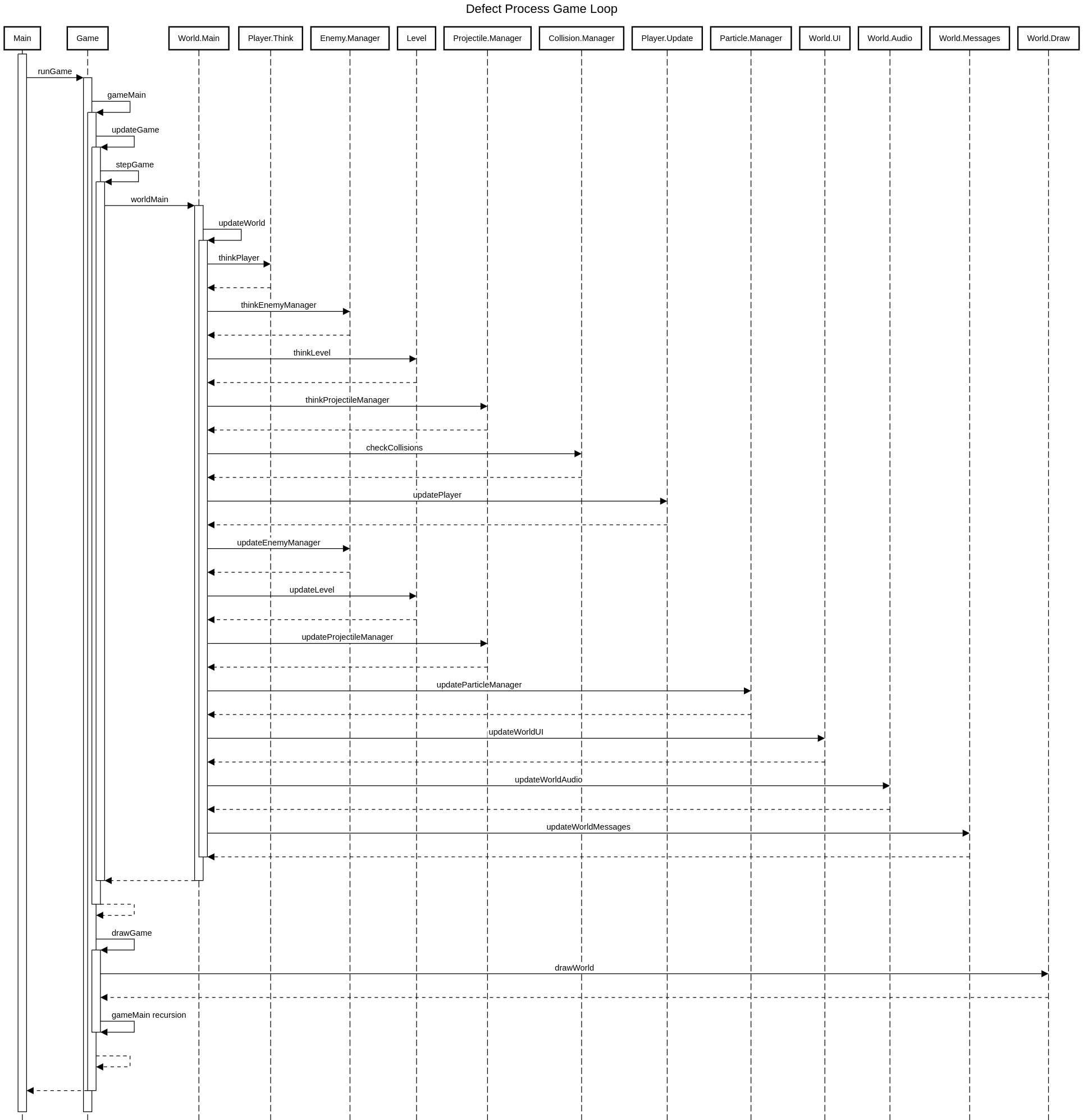
In the next section we want to have a closer look at the message passing mechanism which is key in understanding the distinction between think and update steps of the dynamic objects.
Messaging ¶
The heart of the engine is without any doubt the updateWorld function implemented in World.Main.hs, as it implements the servicing of the dynamic objects through a split in a think and an update phase as already outlined in the Defect Process Overview Message Passing Rules Everything Around Me. In this section the aim is to better understand this split of think and update phases and how they are connected through message passing.
There are a number of subsystems which are serviced in updateWorld, but to understand messaging properly we are going to focus simply on the World messages. The relevant parts, including the player bits in updateWorld are:
updateWorld :: GameMode -> World -> AppEnv BaseMsgsPhase World
updateWorld prevGameMode world = do
let player = _player world
...
withMsgsPhase @ThinkPlayerMsgsPhase (thinkPlayer player)
...
player' <- withMsgsPhase @UpdatePlayerMsgsPhase (updatePlayer player)
...
world' = world
{ _player = player'
, ...
}
withMsgsPhase @UpdateWorldMsgsPhase (updateWorldMessages world')
We first look at how messages are processed, more specifically the World messages. This happens when updateWorld returns the updated world’ where in the last line all messages related to the world are processed through updateWorldMessages. In this function all world messages such as WorldMsgSwitchRoom, WorldMsgScreenshake, WorldMsgPause and others are processed, which are pretty self explanatory. The relevant function to fetch all world-specific messages is readMsgs:
readMsgs :: forall p m a. (MsgsRead p m, AllowMsgRead p a) => m [a]
readMsgs = readMsgsTo @p NullId
The question is, how readMsgs is able to fetch all world-related messages, given its polymorphic type? readMsgs delegates to readMsgsTo, which is defined in the type class MsgsRead and implemented for AppEnv in AppEnv.Types. This method returns the payload of all messages for a given MsgId, hold by AppEnvWriteData { _messages :: M.Map MsgId [MsgInternal] }. Now, the interesting thing is that MsgId is not passed as parameter to readMsgs but it is actually inferred from the types, where the type variable is bound in @p, a feature supported by the TypeApplications language extension.updateWorldMessages specifies this type as UpdateWorldMsgsPhase:
updateWorldMessages :: (MonadIO m, MsgsRead UpdateWorldMsgsPhase m) => World -> m World
updateWorldMessages world = foldlM processMsg world =<< readMsgs
But where do these world messages originate from? All over the game! Lets see where WorldMsgSwitchRoom is sent from. It is sent from Collision.Level.checkRoomPortalPlayerCollisions when the collection detection has found out that the player has walked into the exit portal of the current room. In this case the WorldMsgSwitchRoom message is created and eventually with a bunch of other collision detection messages written to AppEnvWriteData { _messages :: M.Map MsgId [MsgInternal] } using the writeMsgs method from the MsgsWrite type class.
Therefore altough the way the messaging system is implemented using advanced type-level magic from Haskell, in the end it is quite straightforward. For every message type such as World, Player, Audio, Collision, there is an entry in the AppEnvWriteData message Map where every entry is a list of messages where new messages are enqueued in a specific order. This allows to batch all relevant messages in the think phase and consume them in the subsequent update phase in all relevant subsystems without the need to pass around lists of messages. Although elegant and flexible, it makes the control flow more difficult to understand though.
Game State Simulatiom ¶
The game state is simulated from Game.updateGame, which will eventually call into World.Main.updateWorld which does the (physics) simulations by calling into all subsystems as pointed out above.
This function first reads all configs and then updates the time, that is it computes and saves the time delta from the previous frame also known as frame time. The time delta is the foundation for how many simulation steps are actually calculated. Generally every game is updating its game objects (the agents in the Agent-Based Simulation) relative to the frame time. If an object is moving with a given speed v meter per second, then the position in each frame depends on the position in the previous frame, yielding a change in position ∆x = v∆t, which is meter (or whichever unit the game defines their models/world in) per frame. The position of the next frame is then: x2 = x1 + ∆x = x1 + v∆t. Early games ignored ∆t altogether and instead specified the speeds of objects directly in terms of meters per frame. In other words, they were specifying object speeds in terms of ∆x = v instead in terms of v∆t, leading to faster object movement when hardware became faster.
Computing the new position based on the current position multiplied by ∆t is a simple form of numerical integration known as the Explicit Euler Method. It works well as long as the speeds of the objects are roughly constant. Variable speeds require more complex integration methods (Runge-Kutta). All numerical integration echniques make use of the elapsed frame time ∆t in one way or another.
Defect Process updates with a fixed delta time value of 120Hz for the simulation while retaining the ability to render at different framerates whatever the hardware allows for. Key to understand the actual implementation is the article Fix your Timestep, which we are briefly summarising below.
The key to arrive at fixed 120Hz for simulation and arbitrary FPS for rendering is to decouple the simulation and rendering updates. For example if the renderer updates with 60Hz (that is 60 FPS), then for each frame, the simulation needs to run twice. However, on systems with powerful hardware or games which are not renderer bound, it could be very well the case that the renderer performs 180 FPS. In this case we update every 3rd frame with a fixed time delta of 1/120. We need to be able to adopt to varying frame rates due to scene complexity and other influences, thus we need a general solution. The idea as pointed out in the article is to let the renderer produce time and the simulation consume it in discrete 1/120 sized steps.
The way Game.updateGame achieves this is by, after having updated the time, calling into step, a function defined in the closure of updateGame, which implements the very mechanism described in Fix your Timestep.
step :: Window -> Configs -> Game -> AppEnv BaseMsgsPhase (Window, Configs, Game)
step win cfgs gm =
let
time = _time gm
diffSecs = _diffSecs time
in if
| diffSecs < timeStep -> return (win, cfgs, gm)
| otherwise -> do
clearAppEnvMsgs
win' <- withMsgsPhase @WindowMsgsPhase (updateWindow win)
gm' <- stepGame win' cfgs gm
asyncStatus <- loadMainThreadAsyncData
time' <- do
elapsedTime <- updateTime time
return $ case asyncStatus of
MainThreadLoadedAsyncData
| _diffSecs elapsedTime > timeStep -> updateTimeDiffSecs timeStep elapsedTime
_ -> updateTimeDiffSecs (diffSecs - timeStep) time
result <- withAppEnvReadData (_inputState win') cfgs $
let
world = _world (gm' :: Game)
console = _console (gm' :: Game)
in withMsgsPhase @ConsoleMsgsPhase (updateConsole world console)
let
win'' = win' {_inputState = clearInputState $ _inputState win'}
cfgs' = _configs (result :: ConsoleUpdateResult)
step win'' cfgs' $ gm'
{ _world = _world (result :: ConsoleUpdateResult)
, _time = time'
, _console = _console (result :: ConsoleUpdateResult)
}
The key is diffSecs, which holds the renderer-produced time. If this value is less than 1/120 (Constants.timeStep) that means that the simulation as performed by stepGame has consumed enough rendering time, that is it has done enough updates in relation to the renderer. If diffSecs still holds more time to conumse, then one simulation step will be performed by calling into stepGame. After this the time will be updated by reducing diffSecs by timeStep, that is the simulation part consumes a part of the renderer-produced time. Eventually, step is going to call itself recursively because more steps might be necessary, depending on how much time is left in diffSecs.
This concludes the simulation part. It is again important to note that no rendering is happening in any of these functions, and they are strictly concerned with updating the game state at stable 120Hz.
Rendering ¶
Rendering happens after world simulation in a call to Game.drawGame. This functions takes a value of type Lerp, which is set in the graphics state by setGraphicsLerp. What is this Lerp value? Lerp stands for Linear Interpolation and it is computed by Game.gameMain when calling Game.drawGame:
let
diffSecs = _diffSecs $ _time gm
world = _world (gm :: Game)
lerp
| worldIsHitlag world = Lerp 0.0
| otherwise = Lerp $ diffSecs / timeStep
withMsgsPhase @DrawMsgsPhase (drawGame lerp gm)
What is lerped is the remaining time which is not fully consumed in the simulation process in case the rendering time and simulation rate do not have exact multiples, such in the case of 50Hz rendering and 120Hz simulation rate. This remaining time is effectively a measure of just how much more time is required before another whole physics step can be taken. This value is used to get a blending factor between the previous and current physics state simply by dividing by dt. This is done in the above function with the result being the Lerp value in the range between 0 and 1, which is then passed to the rendering part where subsystems can interpolate accordingly.
The rendering then happens from World.Draw.drawWorld where calls to various subsystems go for rendering: the world itself with the camera, current room (level), enemies, player, projectiles, particles, worldUI.
Defect Process is a true 2D game, which means everything renders in the form of 2D images. An alternative would be to use 3D models which are rendered from a side-scroller platformer perspective, but Defect Process went for a true 2D style. In such a style everything is basically rendered as 2D images, where large images (textures) form the background and smaller images, called sprites, are used to render animated and static objects in the foreground such as players, enemies, platforms,…
Defect Process is relying on SDL2 for all rendering related stuff and is doing this through the SDL2 bindings library. SDL2 does not provide out-of-the-box functionality for animating images, which is what Defect Process implements on top of the SDL2 library through its own 2D Rendering Engine. The key to this is the Sprite type:
data Sprite = Sprite
{ _filePath :: FilePath
, _images :: [Image]
, _frameSecs :: [Secs]
, _frameIndex :: FrameIndex
, _numFrames :: Int
, _frameChanged :: Bool
, _loopData :: Maybe LoopData
, _frameTags :: [FrameTag]
, _elapsedSecs :: Secs
}
data Image = Image
{ _texture :: Texture
, _subRect :: SubRect
, _originPos :: Pos2
, _topLeftOffset :: Pos2
}
data Texture = Texture
{ _id :: Id Texture
, _sdlTexture :: SDL.Texture
, _width :: Int
, _height :: Int
}
The important part of Sprite is the list of Images in _images, which are the individual still images. Image holds a Texture type which then maps down to a SDL.Texture, which is where Defect Process and SDL2 finally meet.
Animating the Sprite is happening by playing back the list of Images in succession which renders them as an animation. To be able to do this, for each image, the duration it needs to be displayed is stored in _frameSecs. The index of the current image (frame) is stored in _frameIndex. Also, Sprite stores _elapsedSecs to know whether the animation has finished or not yet. Additionally there is data on how to continue after the animation has finished, such as start over again.
Therefore, sprite animation is simply a matter of iterating through the list of images over a specific time frame, equally specified in the sprite itself. This is implemented in Window.Graphics.Sprite.updateSprite:
updateSprite :: Sprite -> Sprite
updateSprite spr
| spriteFinished spr = spr
| otherwise = spr
{ _frameSecs = secs'
, _images = images'
, _frameIndex = frameIndex'
, _frameChanged = newFrame
, _elapsedSecs = _elapsedSecs spr + timeStep
}
where
sec = maybe 0.0 (subtract timeStep) (listToMaybe $ _frameSecs spr)
advFrame = sec <= frameSecsEpsilon
images = _images spr
lastFrame = null $ safeTail images
newFrame = advFrame && not lastFrame
secs = safeTail $ _frameSecs spr
secs' = if advFrame then secs else sec:secs
frameIndex = _frameIndex spr
frameIndex' = if newFrame then frameIndex + 1 else frameIndex
-- let last frame linger when sprite is done
images' = if newFrame then safeTail images else images
Now, the question is where is updateSprite called from? It is obviously called from the various update phase functions such as Player.Update.updatePlayer because it is there where the information is available what the player is doing next and where the player state for the next step is computed, therefore changing the player state, which also includes the animated player sprite. The update of the players sprite will then eventually lead to the rendering of the next frame of the current players sprite through Player.Draw.drawPlayer which is called from Game.drawGame -> World.Draw.drawWorld.
Audio ¶
Defect Process uses the FMOD sound effects engine for its audio output. Due to the fact that FMOD has no Haskell bindings, Defect Process has implemented them itself, using foreign-function calls through the ForeignFunctionInterface language extension (FFI). The essential module is Audio.Fmod which contains the bindings to the C functions, which are implemented in Audio.Fmod.wrapper.c. FMOD needs periodic servicing, which is done through Audio.Fmod.updateFmod called from Game.stepGame.
FMOD is able to play the sounds relative to the player, for example if an enemy is right to the player then the sound the enemy makes is rendered in a way that the player perceives the sound to the right of their current position. For this to work properly, the player position needs to be sent to FMOD so it can render the other sound sources relative to this position. Defect Process makes use of this feature as well and therefore updates the position of the player in terms of FMOD too, which happens from World.Main.updateWorld
audio' <- withMsgsPhase @UpdateAudioMsgsPhase (updateWorldAudio audio)
updateWorldAudio is to be found in World.Audio.
updateWorldAudio
:: (ConfigsRead m, GraphicsRead m, MonadIO m, MsgsReadWrite UpdateAudioMsgsPhase m)
=> WorldAudio
-> m WorldAudio
updateWorldAudio worldAudio = do
setFmodCameraWorldPos =<< getCameraPos
...
The call to setFmodCameraWorldPos does the necessary update by calling through FFI into c_setCameraWorldPosX from Audio.Fmod:
setFmodCameraWorldPos :: MonadIO m => Pos2 -> m ()
setFmodCameraWorldPos cameraPos = liftIO (c_setCameraWorldPosX cameraX)
where cameraX = realToFrac $ vecX cameraPos
The function setCameraWorldPosX in Audio.Fmod.wrapper.c ultimately just sets a global variable, which is used in subsequent computations of other functions to render the sound effects relative to the players position:
void setCameraWorldPosX(float cameraPosVecX) {
cameraWorldPosVecX = cameraPosVecX;
}
Takeaways ¶
I am going to take away the following things and learnings for future Haskell projects of mine
- Module structure. Considering Module A follow the convention of having A.Types.hs, A.SubModule.hs, A.SubModule.Types.hs and so on, for example Windows.Types.hs, Window.Graphics.hs, Window.Graphics.Types.
- Three Layer Cake approach seems to be a pragmatic approach by defining various capabilities through type classes and then provide implementations for them over some “god” type which is based on some
ReaderT IOvariant. In Defect Process the “god” type isAppEnvas defined in AppEnv.Types. I think for applications where there is no large and complex domain model, the Three Layer Cake approach is the way to go, however at the moment I would prefer Free Monads when dealing with a complex Domain Model, which needs to be represented on its own. - The sheer use of phantom types throughout the code base. I have read and seen phantom types in other code and examples but never actually seen it that widely used. Defect Process demonstrates their usefulness in software design!
- The simplicity and elegance of the architecture as well as its pragmatic approach. Although ultimately running and having access to IO, with the clear structure and separation of concerns there is still very clear where mutations happen and where not, thus allowing for quite easy reasoning about side effects. So far I had only experience in a very different approach to Game programming in Haskell, which focuses on purity and testability using Monadic Stream Functions based on Arrows, which was undertaken by Ivan Perez in his doctoral thesis and publications.
Conclusions ¶
While digging into the source code of Defect Process I found the code base to be tremendously clean and disciplined and I dare to say that sometimes it is simply beautiful. However, I also realised how little I knew of Haskell. Despite using it for more than 6 years, I have come across quite a few new things and tricks such as the TypeApplications extension and phantom types.
I found it difficult to understand what was going on on a first glimpse. After I studied various parts more in-depth it was pretty clear. This experience is new to me, coming from an OO background with years of experience in the industry and teaching. With OO languges in a well designed code base I basically understand immediately what is going on and what the flow is - with Haskell I have still troubles. I think this is due to two reasons: 1st I don’t have nearly as much experience in Haskell as I have in OO languages and 2nd at the moment I believe that it lies in the nature of functional programming, where functions just “float around” with no context, as they would have with OO (where they would belong to objects), this lack of context makes it sometimes difficult to understand where the functions really originate. Then again I think this is a perception caused by my lower experience in Haskell and I guess with more experience this perception will shift and might even go away.
Another thing is that I realised that although I know a fair bit about game engines I know mostly about 3D engines and have basically no idea how to approach a 2D side scroller, which I realised has a fundamentally different approach. This obviously made it much harder for me to understand the source code, because I simply did not know the specific domain.
What surprised me is that there are 0 tests. I assume they have been removed from the GitHub repository, because I can hardly imagine that this game with more tahn 50k LoC was developed with 0 tests. However I believe that it is actually possible with Haskell but can only be pulled off by a really strong developer.
Another thing which I found interesting is that the game is not using any scripting language to define enemy behaviour or level related functionality. Assuming the game was developed by a single person (Garrick Chin) it actually makes sense not using a scripting language especially when the whole engine was written in a language with a strong, static type system.
About my Analysis Process (added 29/12/2022) ¶
It is hard to create estimates in retrospect but I guess the whole analysis process including building, reading all related articles and writing the text cost me about 10-15 hours. Here is some advice to understand such a code base and info on how I approached it.
-
Don’t try to understand everything, such a large code base WILL overwhelm you anyway, no matter what you do and how well the code is structured. Break it down step-by-step going layer-by-layer from outer to inner. Conciously ignore details and try to get the essence of the code you are currently inspecting. This only works if the code base is well organised, disciplined and follows good engineering principles - which in my opinion Defect Process is and does - otherwise you are going to have a real hard time. Then again I think a high-quality Haskell code base is easier to understand than a high-quality OO one, due to, well… side effects. In OO the challenge is to understand the web of connected objects through which data flows due to side effects (mutations). In Haskell the challenge is to understand the type abstractions, the side effects are almost always clear - except when using an IORef within a ReaderT IO.
-
You need to be an advanced programmer in the respective paradigm and language, because as everyone knows, some concepts in Haskell are hard to grasp properly. Yes, you can understand certain concepts on an intellectual level but I think that only when it permeates your thinking when inspecting a code base you have properly understood it. For example I struggled at first with the phantom types because I have never seen them in action, and had to get a proper introduction to them - Haskell in Depth is a great source for that!
-
Make sure you are taking notes along the way so you can follow your own breadcrumbs and do not get lost - in case you get lost you can backtrack along your notes. At first you are going to make too detailed, technical notes because you are not REALLY understanding what is going on, but the understanding will come eventually - when it does go back and simplyfy your notes so they properly describe ideas instead of technical details. I think I could have simplified some parts of the notes on Defect Process a bit further but then again its also a matter of time and motivation.
-
Read all articles and sources directly related to the code you can find. I think withouth the great Defect Process Overview it would have been much harder to get into the code base. However, to be honest, the lack of more details motivated me to dig into it myself. Also I read the Fix your Timestep article at least 3 times to understand it properly and the idea behind it - only then I understood how Defect Process implemented it.
-
If you understand the domain you are having a MUCH easier time understanding the code base. I have a quite good knowledge of 3D computer graphics, rendering and 3D game engine architecture (having written a very simple game engine in C++ myself many years ago) which helped me a lot but I also realised that a 2D engine works slightly different in some aspects.
-
Do not give up if you don’t understand something at first and give yourself time. I had to leave some details open, marking them with TODOs in my notes and come back to them later until I had a better understanding of the bigger picture. Also take some rest if you are stuck. Understanding a big code base is exhausting and your mind will work on it even if you are not actively thinking about it - this is when sudden insight comes.
-
Use tools, with the most important thing to have is a good IDE with a proper language plugin. I am using VS Code with its Haskell plugin, which works great, however I have to say that the Haskell plugin did not help too much and I did not rely on it but rather I was making heavy use of the search functionality of VS Code.